Introduction
This article aims to provide an overview & guide to Gherkin. It should help BAs that have been asked to write scenarios …. work in BDD teams … write feature files … or create acceptance tests using the Given/When/Then format.
I’ll provide examples of the Gherkin syntax, why Gherkin is used & how it fits into BDD.
What is this Gherkin you speak of?
Gherkin is a language used to write acceptance tests. BA’s use Gherkin to specify how they want the system to behave in certain scenarios.
My personal definition of Gherkin is: “A business readable language used to express the system’s behaviour. The language can be understood by an automation tool called Cucumber.”
It’s a simple language. There are 10 key words (e.g. Given, When, Then). Because it’s a simple language, it’s understandable by the business. As well as being understandable by the business, Gherkin can be understood by an automation tool called Cucumber. That means Cucumber can interpret Gherkin and use it to drive automated tests. This links BA requirements to automated tests.
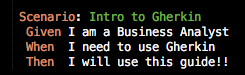
Below is an example of an acceptance test written in Gherkin. A BA may write the acceptance test independently, or as a team effort. Each scenario will test one example of the system’s behaviour:

The system’s behaviour needs to match the acceptance tests/scenarios. A feature may have many scenarios that need to pass. For example with a login component: in one scenario (incorrect password 3 times) a user should be locked out. In another scenario (incorrect password 2 times) a user should see a warning error message etc.
The 10 key words of Gherkin are:
- Given
- When
- Then
- And
- But
- Scenario
- Feature
- Background
- Scenario Outline
- Examples
We’ll go through each key word soon.
Why use Gherkin?
There are two key reasons to use Gherkin:
- Gherkin allows Business Analysts to document acceptance tests in a language developers, QA & the business can understand (i.e. the language of Gherkin). By having a common language to describe acceptance tests, it encourages collaboration and a common understanding of the tests being run.

2. Gherkin also links acceptance tests (GIVEN/WHEN/THEN) directly to automated tests. This is because Cucumber can understand Gherkin. Essentially it means if a BA changes an acceptance test – the developer’s underlying Cucumber test should fail and a red light should start flashing!! Therefore we can be confident that the system matches the BA’s specification. It’s an executable specification. It links requirements, tests and code together. It means the requirements are a living document that need to be kept up to date – otherwise automated tests will fail! Similarly, if the documentation changes and the code doesn’t change – a test will fail which is also good 🙂
As part of BDD, teams want to write many automated tests to improve their confidence in the product/releases. Teams want these tests to be understandable + valuable. Gherkin acceptance tests help with that!! Gherkin adds power to the acceptance tests being written by a BA – because they are directly executed as Cucumber automated tests.
Basic Syntax
Let’s go through the 10 key words.
- Given, When, Then, Scenario

Above is a simple acceptance test. It uses 4 of the 10 key Gherkin words.
Given. This puts the system in a known state. It’s a set of key pre-conditions for a scenario (e.g. user has logged in, user has money in their account etc)
When. This is the key action a user will take. It’s the action that leads to an outcome
Then. This is the observable outcome. It’s what happens after the user makes that action
Scenario. This is used to describe the scenario & give it a title. The reason we do this is because a feature or user story will likely have multiple scenarios. Giving each scenario a title means people can understand what is being tested without having to read all the Given/When/Thens. A scenario title should be succinct. Some people follow “the Friends format” e.g. The one where …. the user has insufficient funds.
- And

This is used when a scenario is more complicated. It can be used in association with Given, When, or Then. Best practice is to avoid having lots of Ands. Having lots of Ands can indicate that a scenario contains unnecessary information – or that a scenario is infact multiple scenarios.
Some people avoid using And in association with When … because this implies a scenario infact needs to be broken down into multiple scenarios. Typically you only want one when (i.e. action) per scenario.
- But

Can be used in association with Then. It’s used to say something shouldn’t happen as an outcome. I’ve literally never used this one!!
- Feature

Feature is used to give a title for the feature/piece of functionality. A feature contains lots of scenarios. For example “Sign in” might be a feature … or “push alerts” …. it’s the title of a piece of functionality.
The same way that scenarios have titles, feature have titles.
A feature file is a file that contains Acceptance Criteria (bullet points describing the rules / high level behaviour) & Scenarios (these are written in Gherkin; they test instances of the rules). Essentially it can be used to contain all the detail for a feature It’s usually stored on GitHub & its basically a text file with an extension of .feature.
- Background

This sets the context for all scenarios below it. If you find that scenarios have common Given/Ands, Background can be used to eliminate the repetition.
Background is run before each of your scenarios. Scenarios can still have Given/When/Thens.
- Scenario Outline / Examples

These are used together. They are used to combine a set of similar scenarios. Essentially you create a table and enter in values … rather than writing a scenario for each set of values. It can mean you have one scenario rather than 10 similar scenarios & makes the feature file much more readable.
- Other stuff
Tags can be used to group acceptance tests. These aren’t part of Gherkin syntax, but are good practice. For example you can use @manual to identify manual acceptance tests. Or @javascript-disabled, @signed-in-users @edge-case @jira-103. A scenario can contain multiple tags – and you can create your own tags.
Steps are the name of anything below the scenario title. It’s the steps that a test will run through for a scenario (e.g. your Given / When / Then)
How it fits into BDD
As part of BDD the developer will write a test before the code. That means the test will initially fail, because the developer hasn’t write the code yet. It ensures each piece of functionality has automated test coverage
Tests should be behavioural in BDD. They should be a high level tests describing user functionality (i.e. not a unit test). Gherkin ensures behavioural tests are written.
Below is a typical BDD process:

The BA would write a feature file (includes bullet point ACs and Gherkin scenarios). This would be 3 Amigo’d with a developer/QA.
The developer would write step definitions for a scenario:

This would cause the test to fail because there is no code yet to pass the functionality. The developer writes code that means the system behaves as specified. The test passes.
Now if anyone changes the Gherkin scenario – it should result in the test failing.
Automated BDD tests reduce manual testing; this means we can have greater confidence when performing regular releases. By using Gherkin,those automated tests can be understandable by everyone. And the tests are hooked into the BA requirements.

Summary
Hopefully you can see the benefits of using Gherkin. I’ve tried to explain the what Gherkin is, why it’s used & the key syntax.
Hopefully the article provided a useful overview of Gherkin.
You should be able to take this little Gherkin quiz !!

Answers are below:
1 C
2 G
3 B
4 D
5 E
6 I
7 J
8 F
9 A
10 H